
Sumeet Khatri
Software / AI Engineer (New Grad-2026)
Strong C++ systems skills, Python backend experience, and hands-on ML infrastructure expertise. Built high-performance storage engines, low-latency inference systems, and scalable ML training workflows.
Work Experience
Software Engineer
STW Services LLP · Pune- Engineered an end-to-end inventory synchronization pipeline across seller and buyer systems, preventing over-ordering and enforcing accurate stock limits in high-volume auction transactions.
- Built real-time aggregation workflows computing inventory from distributed seller records, eliminating 5K+ unit over-purchase scenarios and improving order reliability in production environments.
- Optimized reporting pipelines using refined query filters and time-window logic, eliminating empty datasets and ensuring accurate daily/weekly analytics for operational decision-making.
- Revamped admin dashboard with grouped data models and drill-down interfaces, improving large-scale inventory visibility and reducing manual inspection effort for operational teams.
Machine Learning Engineer
Owl AI (Overload Ware Labs AI) · Pune- Fine-tuned LLaMA-3.2 3B Instruct using QLoRA (4-bit NF4 quantization + LoRA rank=16) on the ServiceNow R1 Distill dataset (172K reasoning samples) for step-by-step chain-of-thought generation.
- Reduced GPU memory footprint from ~12GB (FP32 equivalent) to ~3GB using block-wise 4-bit quantization.
- Configured parameter-efficient training by injecting LoRA adapters into Q, K, V, O projection layers and MLP blocks, training only low-rank matrices instead of full 3B parameters.
- Implemented supervised fine-tuning with AdamW optimizer, achieving final training loss ~0.48 after 60 epochs.
Future Goals
Building RedOpsAI – The Future of Web Security
Over the next six months, my goal is to build RedOpsAI, a SaaS platform that makes website security testing simple and effective. The platform will provide safe and transparent scans, showing live visual feedback of potential risks without causing any harm to the site.
Certifications
Flagship Project
LSM-Tree Key-Value Storage Engine
Feb 2026 – Apr 2026 · C++17, STL, CMake, GoogleTest
- Designed and implemented a zero-dependency LSM-tree storage engine in C++17 with WAL, MemTables, SSTables, and compaction, sustaining ~225K writes/sec and ~2.8M cached reads/sec (0.23µs p50).
- Engineered a double-hashing Bloom filter and O(1) LRU block cache to optimize read amplification under Zipfian workloads, achieving ~99% disk-read elimination and ~9M lookups/sec.
- Built crash-safe WAL with idempotent recovery and optimized compaction strategy, reducing read amplification from O(n) to O(1), validated via p50/p95/p99 latency benchmarks.
- Analyzed trade-offs between write amplification, read latency, and memory usage, tuning compaction and caching policies for optimal throughput under constrained memory.
Technical Arsenal
C++17/20, Python, SQL, JavaScript
Linux, Concurrency, Multithreading, TCP/IP, SIMD/AVX2, OpenMP
Docker, Kafka, GitHub Actions, AWS (EC2), FastAPI
jQuery, Dataverse, OData, Power Automate, HTML/CSS
Supervised/Unsupervised Learning, Ensemble Methods, Feature Engineering, Model Evaluation
Transformers, CNNs, RNN/LSTM, Transfer Learning, Fine-Tuning, QLoRA
PyTorch, Transformers, QLoRA, vLLM, FAISS, LLM Inference
Featured Projects
KVInfer – GPT-2 Inference Engine
Nov 2025 – Mar 2026
Engineered a C++ GPT-2 inference engine with SIMD and parallelism. Architected a multi-engine process pool with KV-cache and LRU eviction, sustaining 14 concurrent sessions within 8GB/16GB RAM.
C++ Inference Engine – 50M GPT
Nov 2025 – Feb 2026
CPU-optimized C++ inference engine for a 51M-parameter GPT model. Reduced per-token latency from 91.87ms → 35.57ms by eliminating heap allocations, redesigning tensor layout for cache locality, and parallelizing matrix multiplications with OpenMP.

C++ High-Performance Order Matching Engine
Aug 2025 – Jan 2026
Engineered a robust Order Matching Engine in C++20 using std::map for strict price-time priority and std::unordered_map for O(1) lookups. Validated with a comprehensive GoogleTest framework.

Custom-Trained SQL Small Language Model (10M GPT)
Sep 2025 – Oct 2025
Architected a compact 10M-parameter GPT model from scratch in PyTorch. Implemented mixed-precision and gradient accumulation, reducing per-epoch data loading times by over 90%.

ContextEngine: RAG System
Built a full RAG pipeline (BM25 + FAISS) boosting grounded accuracy (42%→71%). Optimized inference using vLLM.

Real-Time Event Stream
Designed an event-driven pipeline for e-commerce data using asynchronous producers/consumers.

Memory-Efficient Fine-Tuning
Implemented a QLoRa (4-bit) pipeline, reducing memory footprint by ~70% on a single T4 GPU.

AI Coder Buddy
AI agent using LangChain that plans and generates multi-file applications, decreasing development cycle time by 30%.

Credit Risk Model
Developed interpretable ML models that improved prediction accuracy by 20% for NBFC clients.
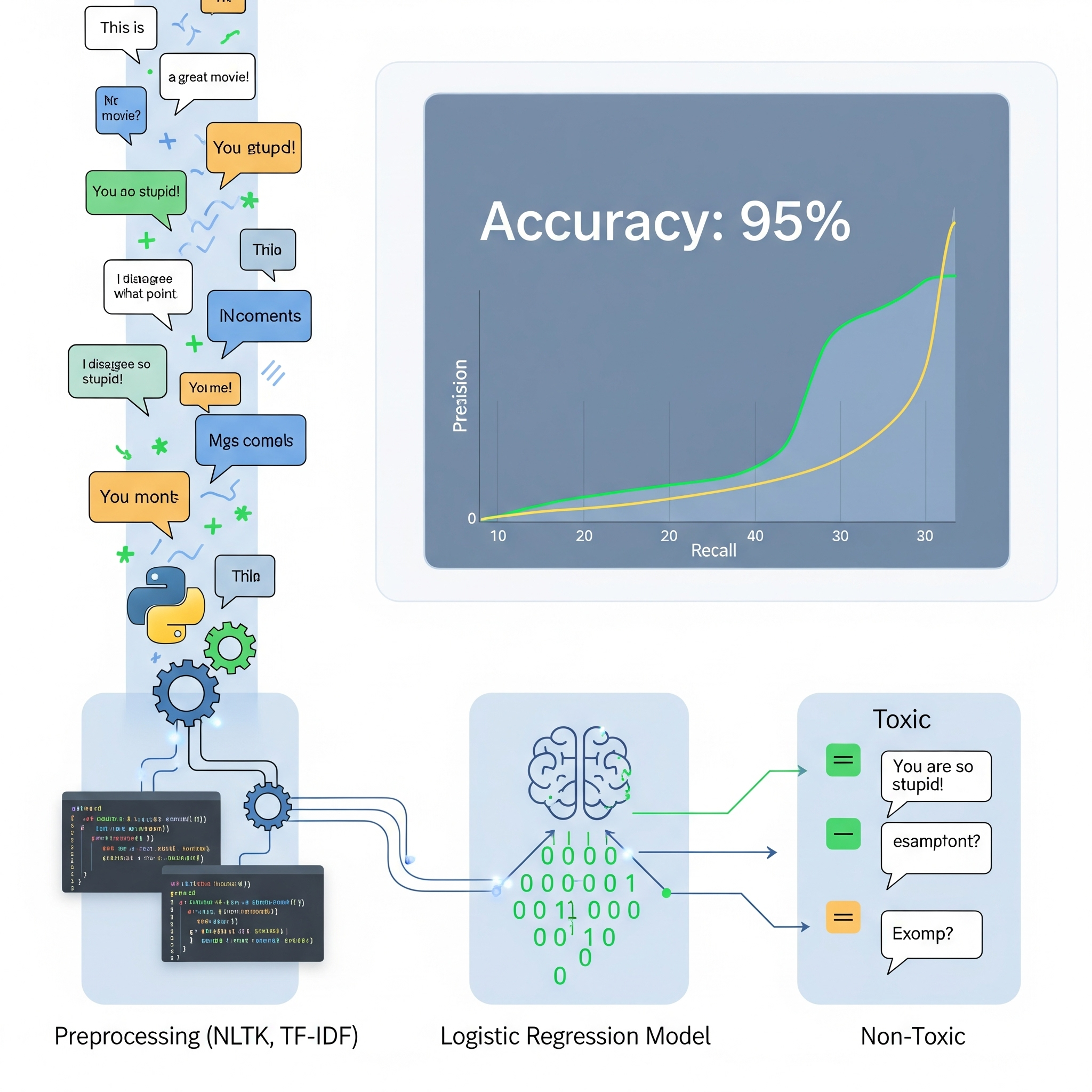
Toxic Message Detector
Trained a text classification model with TF-IDF on 100K+ comments, achieving 95% accuracy.

Multi-Modal Crew AI
Designed a multi-agent framework that automates market research by 70% using specialized 'Researcher' and 'Writer' agents.
Virtual Experience

Virtual Software Internship, Deloitte
Forage
Debugged and refactored a 10k-line Python/SQL codebase. Added connection pooling and regression tests, reducing query failure rate by 40%.

AWS APAC Solutions Architect
Forage | 10/2025 – 11/2025
Designed a scalable Elastic Beanstalk architecture for a client experiencing growth. Translated technical architecture into cost-benefit analysis.